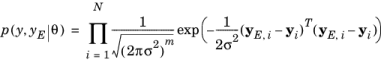Consider a computational model represented by y = M(x,
θ). Here,
x is the vector of experimental parameters,
θ is the vector of calibration parameters, and
y is the vector of QoIs. The experimental parameters
x are independent variables with a known prescribed PDF
p(x). The calibration parameters
θ are parameters to be calibrated from the inverse uncertainty quantification study, the existing knowledge on the calibration parameters are used to prescribe their prior distribution
p(θ). Note that the calibration parameters are considered as inputs to the computer model but are unknown when conducting the experiments. Experiment parameters are known for both the computational model and physical experiment, and they are used to describe the conditions under which the experiments have been conducted.
where δ ∼ Ν(0, ε) represents an additive error and is assumed to be normally distributed with mean equals to 0 and an unknown diagonal covariance matrix
ε = σ2I, where
σ is inferred with the calibration parameters. The definition assumes that the instrumentation, or the computer model, has no systematic bias.
Bayesian inference theory is used to determine the posterior distribution of the calibration parameters which is defined as p(θ| y, yE), where
y and
yE represent the computational model and experimental data, respectively. According to the Bayesian theory, we have
where p(θ) is the prior distribution of the calibration parameter, and
p(y, yE|θ) is the likelihood function. Here the prior and posterior distribution reflects the degree of belief on possible values of
θ before and after considering the experimental data. The likelihood function based on all the experimental data is defined as
where N is the number of experimental data,
m is the number of QoIs. Here, the experimental data is considered as independent samples conditioned on
θ.