|
•
|
The uniform distribution is defined by the upper and lower bounds, and the probability density function (PDF) of the uniform distribution
|
|
•
|
The normal distribution is defined by the mean μ and the standard deviation σ, and the PDF of the normal distribution is
|
|
•
|
The log-normal distribution is defined by the mean μ and the standard deviation σ, and the PDF of the log-normal distribution is
|
|
•
|
The gamma distribution is defined by the shape parameter k and the scale θ, and the PDF of the gamma distribution is
|
|
•
|
The beta distribution is defined by the shape parameter α, the shape parameter deviation β, the upper and lower bounds a and b, respectively, and the PDF of the beta distribution is
|
|
•
|
The Weibull distribution is defined by the shape parameter k and the scale λ, and the PDF of the Weibull distribution is
|
|
•
|
The Gumbel distribution is defined by the location μ and the scale β, and the PDF of the Gumbel distribution is
|
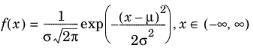 .
.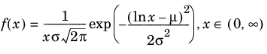 .
.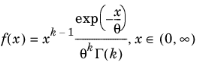 .
.