|
|
|
|
•
|
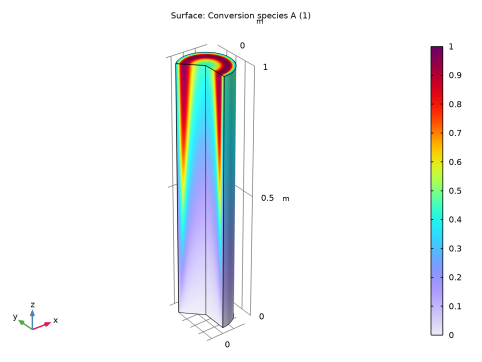
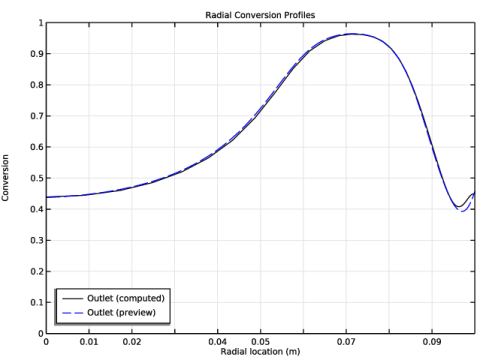
|
1
|
|
2
|
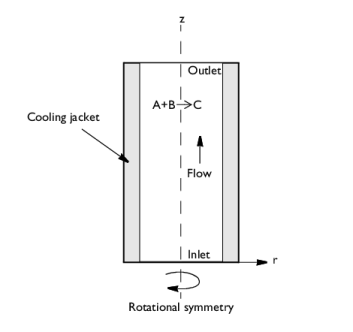
In the Application Libraries window, select COMSOL Multiphysics > Chemical Engineering > tubular_reactor in the tree.
|
|
3
|
Click
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
7
|
|
1
|
|
2
|
|
3
|
|
4
|
Click
|
|
6
|
|
8
|
|
9
|
|
12
|
|
13
|
|
15
|
|
16
|
|
18
|
|
19
|
|
20
|
|
21
|
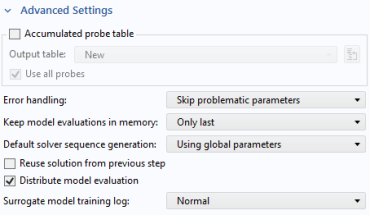
Locate the Advanced Settings section. From the Error handling list, choose Skip problematic parameters.
|
|
22
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
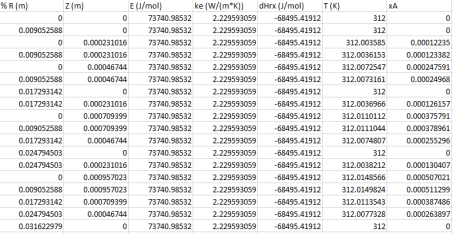
Locate the Parameter Bounds section. Find the First parameter subsection. In the Name text field, type x1.
|
|
6
|
|
7
|
|
8
|
|
9
|
|
1
|
|
2
|
|
3
|
Click
|
|
5
|
|
7
|
|
9
|
|
11
|
|
12
|
|
13
|
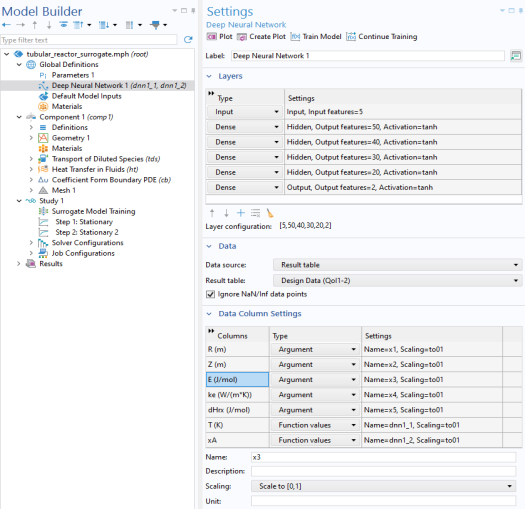
Locate the Data Column Settings section. In the table, enter the following settings:
|
|
15
|
|
17
|
|
18
|
Click
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
1
|
|
2
|
|
3
|
|
4
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
4
|
|
1
|
|
2
|
|
3
|
|
1
|
|
2
|
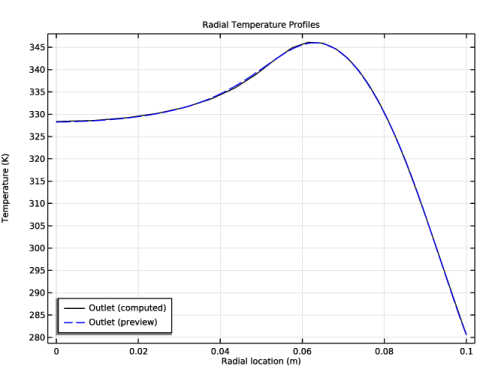
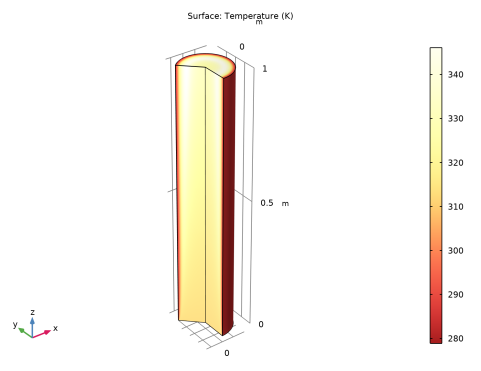
In the Settings window for 3D Plot Group, type Temperature, 3D, Surrogate (Revolved) in the Label text field.
|
|
3
|
|
4
|
|
1
|
|
2
|
|
3
|
|
4
|
|
1
|
|
2
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
1
|
|
2
|
|
3
|
|
4
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
Clear the Additional parallel lines checkbox.
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
8
|
Click to expand the Coloring and Style section. Find the Line style subsection. From the Line list, choose Dashed.
|
|
9
|
|
1
|
|
2
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
7
|
|
8
|
|
9
|
|
1
|
|
2
|
|
4
|
Click
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
Locate the Coloring and Style section. Find the Line style subsection. From the Line list, choose Dashed.
|
|
6
|
|
7
|
|
8
|
|
1
|
|
2
|
|
3
|
|
4
|
|
5
|
|
6
|
|
7
|
|
8
|
|
9
|
|
10
|
|
1
|
|
2
|
|
3
|
Clear the Plot dataset edges checkbox.
|
|
4
|
|
5
|
|
6
|
|
7
|
|
1
|
|
2
|
|
3
|
|
4
|
|
1
|
|
2
|
|
3
|
Clear the Plot dataset edges checkbox.
|
|
4
|
|
5
|
|
1
|
|
2
|
|
3
|
|
4
|