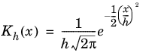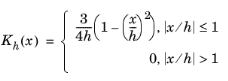Use a Kernel Density Estimation (

) dataset, found under the
More Datasets submenu, to take a table and compute the kernel density estimation (KDE), which is a nonparametric way to estimate the probability density function of a random variable.
From the Dimension list, choose a space dimension for the data:
1 (the default),
2, or
3.
From the Source list, choose
Table (the default) or
Evaluation Group, and then choose the table or evaluation group from the
Table or
Evaluation group list below.
Under Columns, choose which columns that should represent the coordinate values (1–3, depending on the chosen dimension) from the
x-coordinates,
y-coordinates, and
z-coordinates list.
From the Kernel type list, choose which kernel to use:
Gaussian (the default) or
Parabolic (Epanechnikov).
From the Bandwidth list, choose how to specify the bandwidth:
Auto (Silverman’s rule of thumb) (the default), to compute the bandwidth automatically using Silverman’s rule of thumb, or
Manual, to specify the bandwidth
h as a scalar value in the case of 1 dimension. For 2 and 3 dimensions, specify the matrix components of the bandwidth
H. The bandwidth matrix
H must be symmetric, invertible (nonsingular), and positive definite.
Under Input variables, you can edit the names of the input variables that are created in the
x,
y, and
z (depending on the dimension).
From the Resolution list, choose
Automatic (the default) to use an automatically determined resolution, or choose
Manual to define the resolution as a positive integer larger than 1 (default: 10) in the
x resolution,
y resolution, and
z resolution fields (depending on the dimension).
Under Output variable, you can edit the name of the out variable for the KDE value in the
KDE value field.