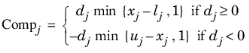If the bounds and linear constraints cannot be satisfied to within t, the problem is declared infeasible. Let
sInf be the corresponding sum of infeasibilities. If
sInf is quite small, it might be appropriate to raise
t by a factor of 10 or 100. Otherwise you should suspect some error in the data.
In practice, the solver uses t as a feasibility tolerance for satisfying the bound and linear constraints in each QP subproblem. If the sum of indefeasibility cannot be reduced to zero, the QP subproblem is declared infeasible. The solver is then in the Elastic mode thereafter (with only the linearized nonlinear constraints defined to be elastic).
The relative function precision is intended to be a measure of the relative accuracy with which the nonlinear functions can be computed. For example, if f(x) is computed as
1000.56789 for some relevant
x and if the first 6 significant digits are known to be correct, the appropriate value for the function precision would be
10−6. (Ideally the functions should have a magnitude of order 1. If all functions are substantially less than 1 in magnitude, the function precision should be the absolute precision. For example, if
f(x) = 1.23456789·
10−4 at some point and if the first 6 significant digits are known to be correct, the appropriate precision would be
10−10.)
When the number of nonlinear variables is large (more than 75) or when the QP problem solver is set to conjugate-gradient, a limited-memory procedure stores a fixed number of BFGS update vectors and a diagonal Hessian approximation. In this case, if hessupd BFGS updates have already been carried out, all but the diagonal elements of the accumulated updates are discarded and the updating process starts again. Broadly speaking, the more updates stored, the better the quality of the approximate Hessian. However, the more vectors stored, the greater the cost of each QP iteration. The default value is likely to give a robust algorithm without significant expense, but faster convergence can sometimes be obtained with significantly fewer updates (for example,
hessupd = 5).
Let rowerr be the maximum nonlinear constraint violation, normalized by the size of the solution. It is required to satisfy
where violi is the violation of the
ith nonlinear constraint. If some of the problem functions are known to be of low accuracy, a larger major feasibility tolerance might be appropriate.
where Compj is an estimate of the complementarity slackness for variable
j. The values
Compj are computed from the final QP solution using the reduced gradients
dj = gj − πT aj, as above. Hence you have
'cholesky' holds the full Cholesky factor
R of the reduced Hessian
ZTHZ. As the QP iterations proceed, the dimension of
R changes with the number of superbasic variables.
'qn' solves the QP subproblem using a quasi-Newton method. In this case,
R is the factor of a quasi-Newton approximate reduced Hessian.
'cg' uses the conjugate-gradient method to solve all systems involving the reduced Hessian. No storage needs to be allocated for a Cholesky factor.
The quasi-Newton QP solver does not require the computation of the exact R at the start of each QP and might be appropriate when the number of superbasics is large but each QP subproblem requires relatively few minor iterations.